The communicative function of an utterance is modeled by the dialogue act which is one of the labels of a structured hierarchy as shown in fig. 1. Once a dialogue act is found (statistically or rule-based) it is attached to the internal representation of the utterance as a label (note that multiple, overlapping communicative functions of a single segment are possible in which case we attach a list of labels).
The propositional content of an utterance is modeled by a number of objects - abstract and physical - that are connected by relations. These objects are instances of an ISA class hierarchy and refer to real-world objects (a small part of the class tree is shown in fig. 2).
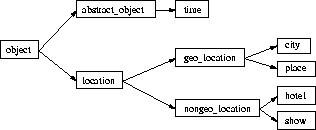
Figure 2: OBJECT subtree of direx class hierarchy
The representation language is called DRL (discourse representation
language), its entities are called DIREXes (discourse
representation expressions). Embedded in this language is a special
time representation language whose expressions are called TEMPEXes [Endriss1998]. An example representation looks like this:
so how about a three o'clock flight out of Hannover
[has_move:[move,has_departure_time:{time_of_day:3}, has_source_location:[city,has_name='hannover']]]
The utterance itself is also represented by a DIREX. It contains slots for the dialogue act, the topic and pointers to above mentioned objects. Due to frequent occurrences of ellipses and anaphora the contents information delivered by shallow extraction is incomplete and has to be extended with the help of context knowledge (see section 4.3 below). The utterance object points to the extended object as well as to the original object delivered by shallow extraction.