Systemübersicht
Im Folgenden stellen wir kurz unsere Systemarchitektur und unsere grafische Benutzerschnittstelle vor.
Außerdem stellen wir ein kurzes Viedo über unsere Benutzersimulation in Aktion bereit.
 |
| SpeechEval Architektur |
Die Architektur des Systems behält die modulare Organisation der meisten SDS bei, die aus Modulen für
Spracherkennung (ASR), Sprachverständnis (NLU), Dialogmanagement, Sprachgenerierung (NLG) und
Sprachsynthese (TTS) bestehen. Da unsere Simulation Sprache als
Schnittstelle zum SDS nutzt, ist die erste Komponente der Architektur ein Spracherkenner, der
als Input den SDS-Prompt nimmt, den er aus der Telefoneverbindung erhät. Die Nutzung von Sprache anstelle von Text oder Absicht als Schnittstelle
der Simulation hat den Vorteil, dass es realistischer und flexibler ist.
Desweiteren müssen simulierte ASR-Fehler nicht künstlich in die Ausgaben eingefügt werden,
und unsere Experimente zeigen, dass die synthetisierte Sprache, die die Simulation an das SDS sendet,
in der Erkennungsrate dem menschlichen Input entspricht.
Die folgenden abbildungen geben einen kurzen Überblick über die SpeechEval-GUI und die Optionen zur
Visualisierung der zugrundeliegenden Wissensbasen.
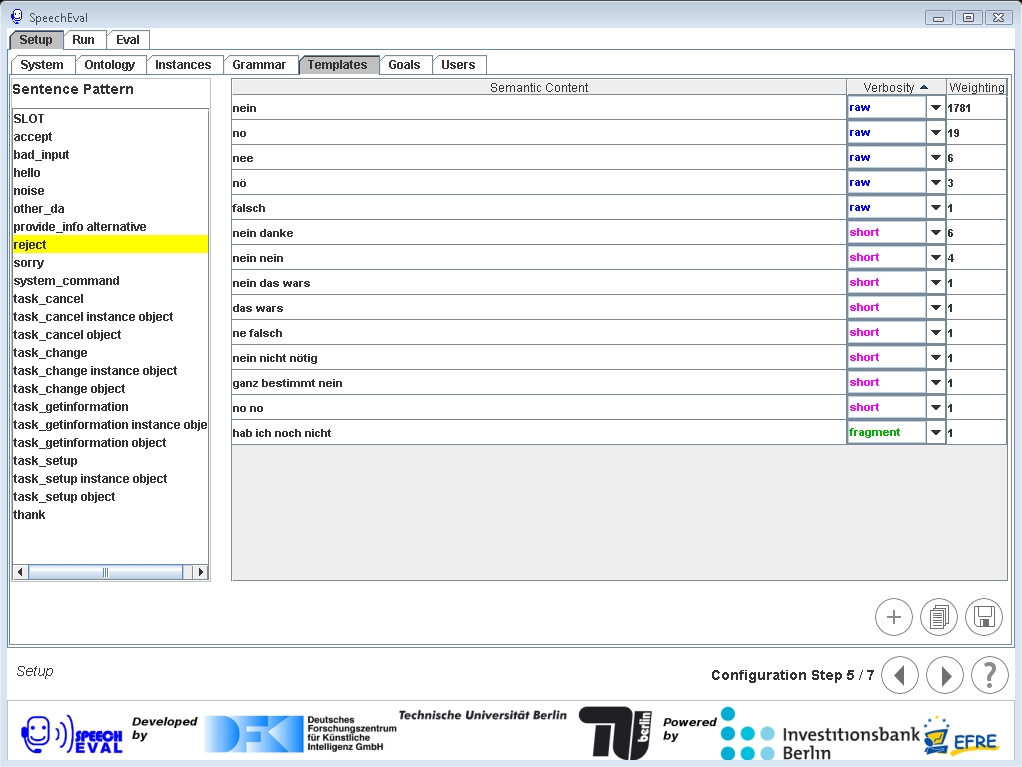 |
| Antworttemplates |
|
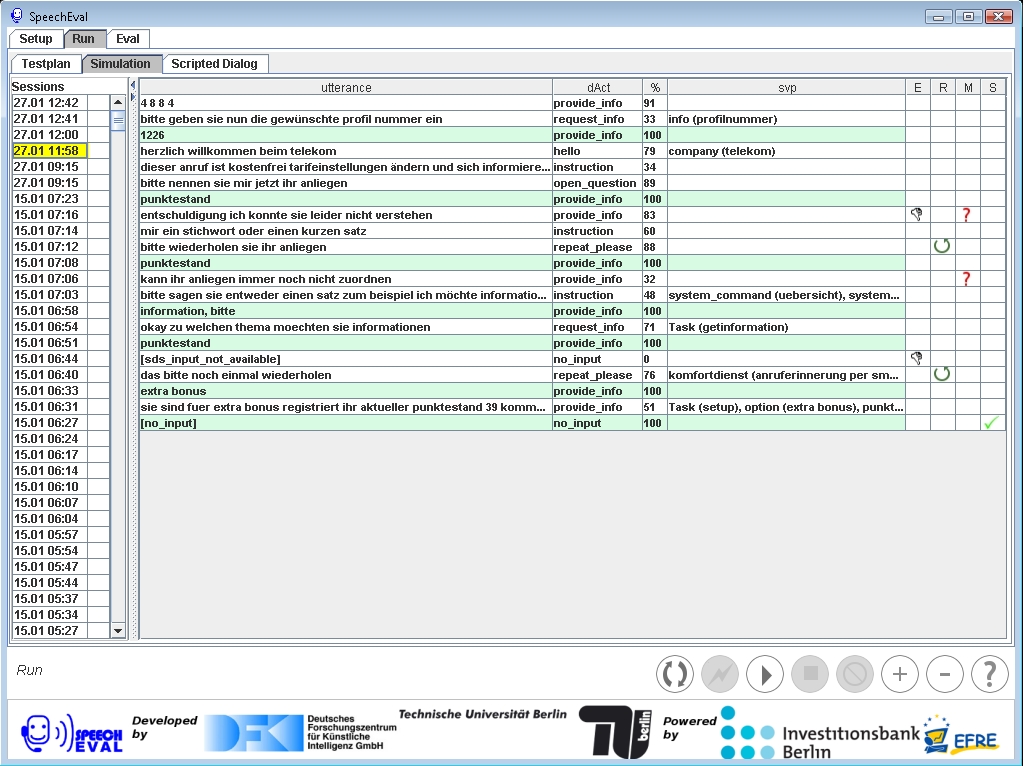 |
| erfolgreicher Simulationslauf |
|
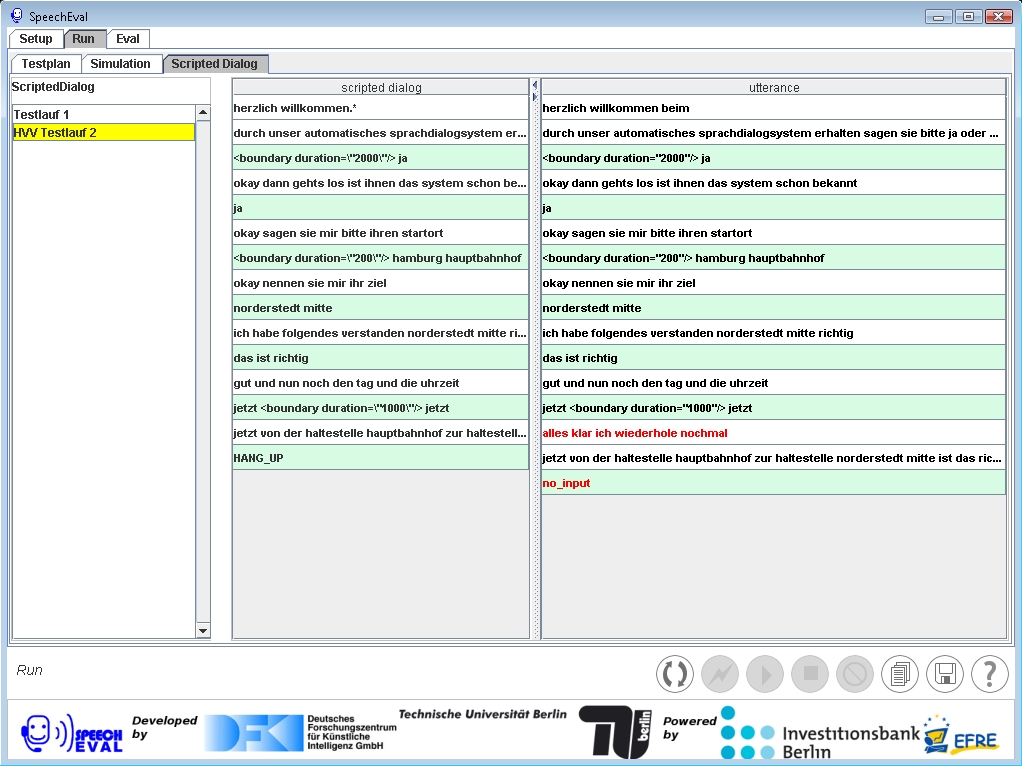 |
| gescripteter Dialog |
|

